특징 기반 컴퓨터 비전 알고리즘의 이해 - 0. 들어가면서
2022. 3. 18.
내가 2022년 현재까지 재학중인 경상국립대학교 컴퓨터과학부 컴퓨터과학전공 알고리즘 연구실에서는 ORB-SLAM이라는 기술을 이용하여 연구 프로젝트를 진행한 바 있다. 해당 프로젝트를 수행하기 위한 기반 지식들을 학습했고, 프레젠테이션을 위한 자료를 만들어 연구실 세미나 시간에 발표하기도 했다. 그러나 이 지식들이 PPT 하나로 정리될 분량이 아니기에 당시 자료에서는 지엽적인 부분을 잘라내기도 했었고, 프로젝트가 끝난 후 더 이상 관련 지식을 접하지 않아 잊혀지게 되는 것이 아쉬워서 공부했던 내용을 정리하여 연재할 예정이다.
연재 방향성
연구 프로젝트를 진행하며 처음으로 컴퓨터 비전에 관련된 공부를 하게 되었다. 기반 지식 없이 좌충우돌하며 학습했기에 많은 어려움이 따르는 것은 당연했다. 혹여나 누군가가 컴퓨터 비전 공부를 피할 수 없는 상황이 되었는데, 아는 정보가 아무것도 없어 불안하게 한 발자국씩 내딛는 느낌일 때 이 글이 그 밑바탕이 되어줄 수 있었으면 좋겠다(되면 좋겠다는 거고 실제로 될 지는 잘 모르겠다).
컴퓨터 비전 알고리즘에는 여러 종류가 있으며, 각각이 논문의 주제거리가 될 정도로 알아야 할 내용이 방대하므로 모든 내용을 다 다루는 것에는 한계가 있다. 따라서, 각 알고리즘의 주요 아이디어와 이를 이해하기 위한 부차적인 지식들을 함께 알아보는 형식을 취하려 한다. 그리고 그 모든 내용 이전에 컴퓨터 비전이라는 것이 무엇인지에 대해 이야기하고 넘어가려 한다.
특징 기반 컴퓨터 비전?
눈앞에 있는 물체를 바라볼 때, 인간은 어떻게 그 물체와 배경을 분리해서 생각할 수 있을까? 또 그 물체를 가까이에서 보든 멀리서 보든, 바로 보든 거꾸로 보든 그 물체임을 알 수 있는 것은 어째서일까? 그 원리를 알아낼 수 있다면, 그리고 이를 알고리즘화할 수 있다면 컴퓨터에도 비슷한 작업을 시킬 수 있지 않을까? 즉, 인간의 시각과 이를 처리하는 뇌의 역할을 컴퓨터가 대신할 수 있게 모방할 수 있지 않을까? 물론 완벽하게 따라할 수는 없겠지만 인간들은 나름대로 머리를 써서 그런 방법들을 만들어냈고, 그것들이 모여 컴퓨터 비전이라는 분야로 발전하였다.

어느날 인간 아무개씨가 너무 심심했던 나머지 위 그림과 같은 직소 퍼즐을 하나 사서 맞추게 되었다고 해보자. 인간 아무개씨는 흩어져있는 퍼즐 조각들을 어떻게 맞춰나갈까? 그림에 보이는 건 하늘과 땅, 그리고 배 한 척이다. 그림에서 면적을 제일 많이 차지하는 하늘은 구름이 넓게 깔려있기 때문에, 각 조각들이 서로 엇비슷해보인다. 하지만 배의 경우, 하늘/땅과 함께 나눠져있는 윤곽을 대강 맞춰보면 수월하게 맞출 수 있을 것 같다. 특히 뾰족하게 끝나는 배의 앞부분부터 맞추기 시작하면 더 쉽게 퍼즐을 완성해나갈 수 있을 것이다. 인간 아무개씨에게는 이런 생각이 아주 자연스럽다. 인간 아무개씨는 어떻게 하늘/땅과 배를 서로 구분할 수 있는 걸까?
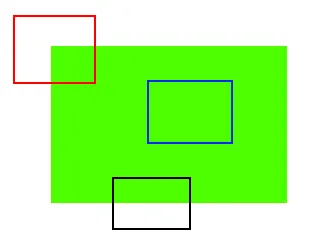
인간 아무개씨가 하늘/땅과 배를 구분할 수 있는 것은 배의 윤곽 부분 색이 하늘/땅의 색과 다르기 때문이다. 하늘의 경우, 어느 조각이든 서로 비슷하게 생겼기 때문에 그 정확한 위치를 한눈에 알아보기 어렵다. 이는 마치 위 그림에서 파란색 사각형 부분과 같은데, 초록색의 꽉 찬 사각형 내부 그 어느 곳을 잘라내도 파란색 사각형의 내부와 똑같기 때문에 해당 부분의 정확한 위치를 알 수 없다. 그러나 검은색 사각형의 경우, 잘은 모르겠지만 초록색 꽉 찬 사각형의 아랫부분을 잘라낸 조각임을 알 수 있다. 그리고 더 나아가 빨간색 사각형의 경우, 초록색 꽉 찬 사각형의 왼쪽 위 귀퉁이를 잘라낸 조각임을 알 수 있다(별도로 그림에 회전변환이 가해지지 않았다는 가정 하에).
이렇게 인간은 이미지의 일부분을 보고 해당 부분이 원래 이미지의 어디에 해당하는 지를 유추해낼 수 있으며, 이미지의 특정 부분에는 그 위치를 짐작할 수 있는 일종의 정보(색상, 질감, 형태 등)가 숨어있다. 이를 일반적으로 이미지의 저수준 특징(low-level feature)이라고 이야기한다. 이런 특징들을 이용한다면 컴퓨터를 이용해 이미지 내에서 배경을 제외한 물체를 찾는 것도 가능하지 않을까? 이러한 접근의 연구 분야를 객체 탐지(Object Detection)라고 한다.
이렇게 찾아낸 물체들이 실제로 어떤 물체인지를 알아내는 것도 중요하다. 이쪽 분야는 객체 인식(Object Recognition)이라는 이름으로 널리 알려져 있으며, 비교적 인공지능의 영역에 가깝다. 그에 비해 객체 탐지는 영상처리의 영역에 가깝다고 볼 수 있다.
결론
이 시리즈에서는 객체 탐지 쪽에 좀 더 비중을 둘 예정이다. 인공지능 쪽에는 크게 관심이 없기도 하고, 내가 실제로 공부했던 게 그쪽에 가깝기도 하기 때문이다. 객체 인식 알고리즘은 딥러닝의 발전 이후로 점점 고도화되고 있어서 나같은 학부생 나부랭이가 할 게 아닌 것 같다. 도망쳐~
다음 글에서는 이미지의 특징을 정의하는 가장 이른 논문 중 하나인 Hans Moravec의 “Obstacle Avoidance and Navigation in the Real World by a Seeing Robot Rover”를 살펴보며 그의 아이디어를 따라가보도록 하겠다.
- Computer Vision, Object Detection